🎉 Accepted by NeurIPS 2024 Datasets and Benchmarks Track.
✨ Top6/121,084 in the Hugging Face Dataset Trending List on Mar. 19th 2024.
🔥 Featured in Daily Papers by AK on Mar. 12nd 2024.
🌟 Downloaded 10000+ on WiseModel.

VidProM is the first dataset featuring 1.67 million unique text-to-video prompts and 6.69 million videos generated from 4 different state-of-the-art diffusion models. It inspires many exciting new research areas, such as Text-to-Video Prompt Engineering, Efficient Video Generation, Fake Video Detection, and Video Copy Detection for Diffusion Models.
Abstract
The arrival of Sora marks a new era for text-to-video diffusion models, bringing significant advancements in video generation and potential applications. However, Sora, along with other text-to-video diffusion models, is highly reliant on prompts, and there is no publicly available dataset that features a study of text-to-video prompts. In this paper, we introduce VidProM, the first large-scale dataset comprising 1.67 Million unique text-to-Video Prompts from real users. Additionally, this dataset includes 6.69 million videos generated by four state-of-the-art diffusion models, alongside some related data. We initially discuss the curation of this large-scale dataset, a process that is both time-consuming and costly. Subsequently, we underscore the need for a new prompt dataset specifically designed for text-to-video generation by illustrating how VidProM differs from DiffusionDB, a large-scale prompt-gallery dataset for image generation. Our extensive and diverse dataset also opens up many exciting new research areas. For instance, we suggest exploring text-to-video prompt engineering, efficient video generation, and video copy detection for diffusion models to develop better, more efficient, and safer models.
Datapoint

Basic information of VidProM and DiffusionDB

Differences between prompts in VidProM and DiffusionDB
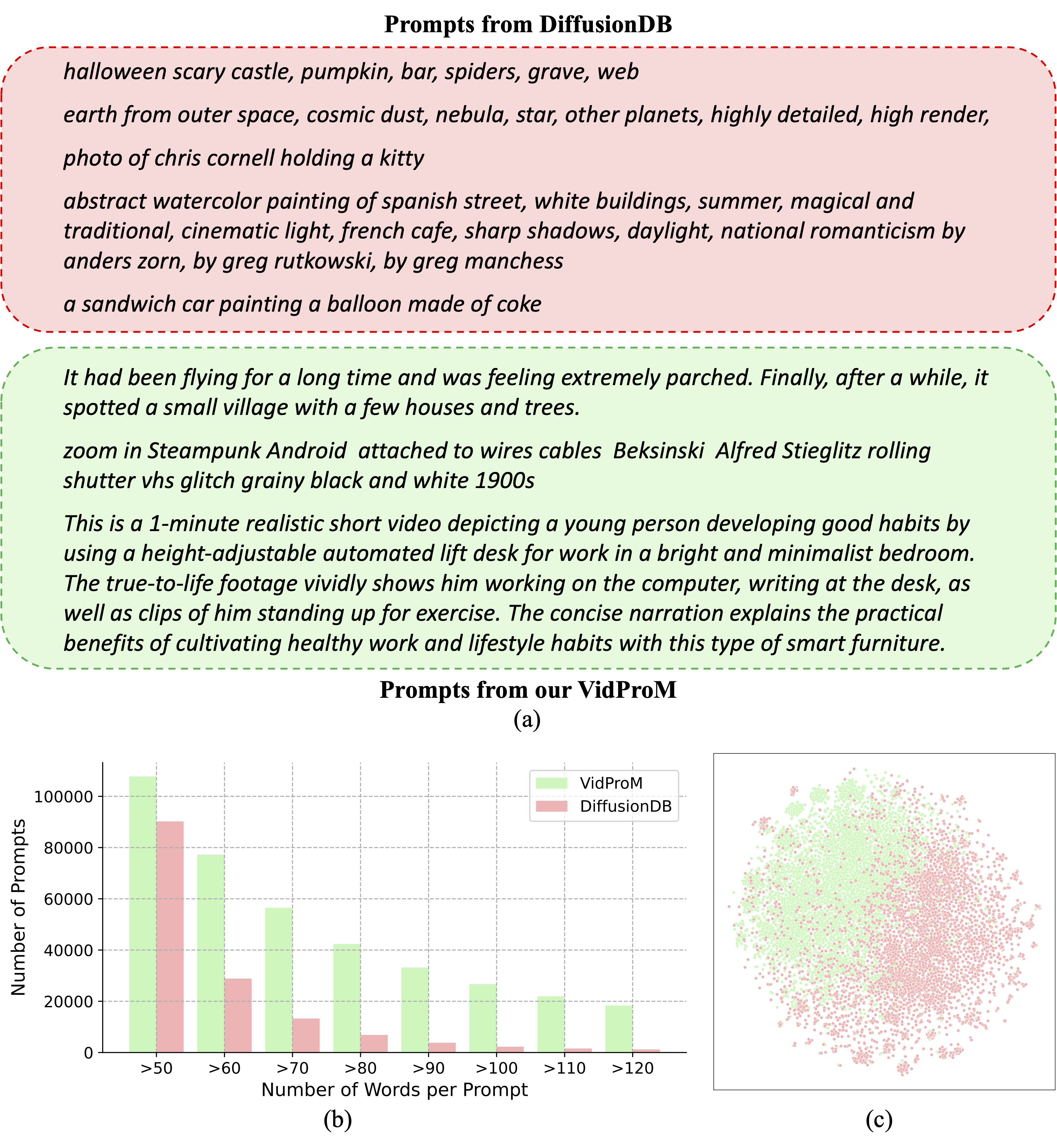
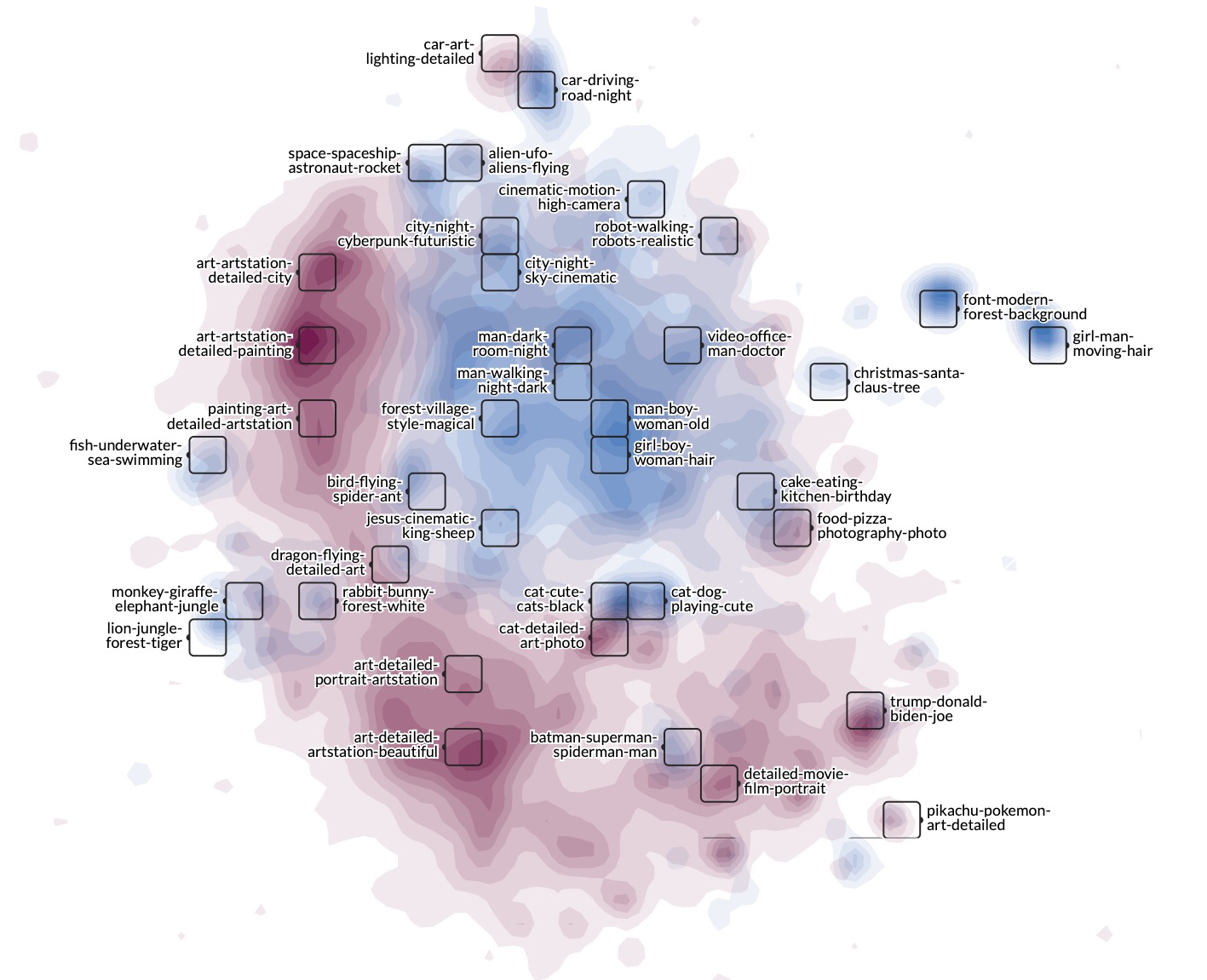
WizMap visualization of prompts in VidProM and DiffusionDB
Paper

VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
Wenhao Wang and Yi Yang
NeurIPS, 2024.
@article{wang2024vidprom,
title={VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models},
author={Wang, Wenhao and Yang, Yi},
journal={Thirty-eighth Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=pYNl76onJL}
}Contact
If you have any questions, feel free to contact Wenhao Wang (wangwenhao0716@gmail.com).
Works using VidProM
We are actively collecting your awesome works using our VidProM. Please let us know if you finish one.
1. Ji, Lichuan, et al. "Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features." Arxiv 2024.
2. Xuan, He, et al. "VIDEOSCORE: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation." EMNLP 2024.
3. Liao, Mingxiang, et al. "Evaluation of Text-to-Video Generation Models: A Dynamics Perspective." NeurIPS 2024.
4. Miao, Yibo, et al. "T2VSafetyBench: Evaluating the Safety of Text-to-Video Generative Models." NeurIPS 2024.
5. Wu, Xun, et al. "Boosting Text-to-Video Generative Model with MLLMs Feedback." NeurIPS 2024.
6. Dai, Josef, et al. "SAFESORA: Towards Safety Alignment of Text2Video Generation via a Human Preference Dataset." NeurIPS 2024.
7. Liu, Joseph, et al. "SmoothCache: A Universal Inference Acceleration Technique for Diffusion Transformers." Arxiv 2024.
8. Wang, Zeqing, et al. "Is this Generated Person Existed in Real-world? Fine-grained Detecting and Calibrating Abnormal Human-body." Arxiv 2024.
9. Jang, MinHyuk, et al. "LVMark: Robust Watermark for latent video diffusion models." Arxiv 2024.
10. Liu, Runtao, et al. "VideoDPO: Omni-Preference Alignment for Video Diffusion Generation." Arxiv 2024.
11. Ji, Jiaming, et al. "Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback." Arxiv 2024.
12. Xu, Jiazheng, et al. "VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation" Arxiv 2024.
13. Wang, Zihan, et al. "What You See Is What Matters: A Novel Visual and Physics-Based Metric for Evaluating Video Generation Quality" Arxiv 2024.
14. Sun, Desen, et al. "FlexCache: Flexible Approximate Cache System for Video Diffusion" Arxiv 2025.
15. Li, Lijun, et al. "T2ISafety: Benchmark for Assessing Fairness, Toxicity, and Privacy in Image Generation" Arxiv 2025.
16. Ni, Zhenliang, et al. "GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video" Arxiv 2025.
17. Wang, Wenhao, et al. "VideoUFO: A Million-Scale User-Focused Dataset for Text-to-Video Generation" Arxiv 2025.
18. Cheng, Jiale, et al. "VPO: Aligning Text-to-Video Generation Models with Prompt Optimization" Arxiv 2025.
19. Xue, Zeyue, et al. "DanceGRPO: Unleashing GRPO on Visual Generation" Arxiv 2025.
20. Liu, Jiayang, et al. "Jailbreaking the Text-to-Video Generative Models" Arxiv 2025.
21. Li, Lijun, et al. "Benchmarking Ethics in Text-to-Image Models: A Holistic Dataset and Evaluator for Fairness, Toxicity, and Privacy" OpenReview 2025.
Acknowledgements
This template was originally made by Phillip Isola and Richard Zhang for a colorful project, and inherits the modifications made by Jason Zhang and Shangzhe Wu. The code can be found here.